


The Era of Retrieval Augmented Generation (RAG)
In the evolving world of generative AI, Retrieval Augmented Generation (RAG) marks a significant advancement, combining retrieval-based model accuracy with generative model creativity. This innovative architecture is specifically designed for tasks that demand precise information retrieval and contextually informed and comprehensible responses. RAG leverages extensive databases and the dynamic capabilities of large language models (LLMs) to generate insightful and accurate results.
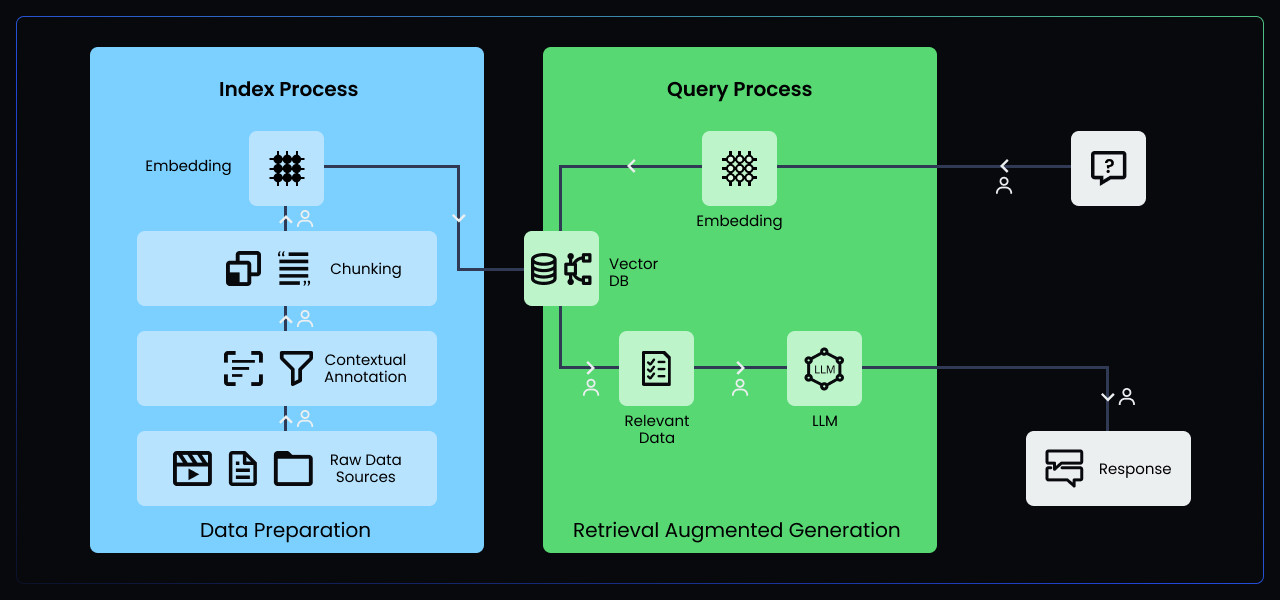
The RAG architecture consists of two main components: data preparation (blue) and the RAG system itself (green). Data preparation involves connecting to raw data sources, annotating data with contextual information, chunking documents into smaller units, and converting those chunks into vector embeddings. Chunking improves coherence, while embeddings enable better semantic matching and retrieval of relevant knowledge for the RAG generator.
The RAG system takes user prompts, searches the embeddings for relevant passages, and sends them to the LLM (Large Language Model) to generate a response. Human involvement is crucial in both data preparation, where domain expertise and context are added to the raw data, and in the RAG system, where humans enhance vector retrieval relevance and provide prompt/response quality assurance.
Where RAG Shines: Optimal Use Cases
RAG architecture is unmatched in its versatility, catering to a spectrum of applications from conversational AI and content creation to complex query resolution in search engines. Its unique ability to ground generative responses in factual, retrieved data makes it especially suited for:
- Customer Support Systems: Providing accurate, context-sensitive answers to customer inquiries.
- Educational Platforms: Offering detailed explanations or answers based on a broad knowledge base.
- Research and Analysis Tools: Distilling complex information into comprehensive summaries.
- Content Generation: Crafting rich, informative, and relevant content across various domains.
Crafting Excellence in RAG: Decisions that Matter
The efficacy of RAG hinges on meticulous decisions across its architecture:
- Data Preparation: Selecting and chunking data into coherent units without losing the contextual essence. Appen's expertise in data annotation and chunking (Step B and C in the diagram) ensures that the data is contextually intact and accurately labeled.
- Embedding Techniques: Choosing the right methods to convert text chunks into embeddings for efficient retrieval.
- Relevance and Ranking: Algorithms for determining the relevance of retrieved data to the user's prompt and their subsequent ranking. Appen's human-in-the-loop approach enhances the relevance and ranking of retrieved data (Step 3 in the diagram).
Quality at the Forefront
Ensuring the highest quality and accuracy in RAG outputs necessitates several considerations:
- Comprehensive Data Annotation: Involving humans to label and categorize data accurately. Appen's data annotation services (Step B in the diagram) ensure precise and contextually relevant data annotation.
- Bias Reduction: Actively seeking and neutralizing biases in both the dataset and the model's responses.
- Continuous Evaluation: Regularly testing the model against a variety of prompts to ensure consistency and reliability. Appen's quality assurance processes help maintain the model's performance over time.
Auto Evaluation Metrics: Monitoring RAG's Precision and Relevance
While the human touch is indispensable in enhancing the quality and integrity of RAG systems, automatic evaluation metrics play a crucial role in continuously monitoring the performance of these architectures. These metrics enable AI teams to swiftly identify areas for improvement, ensuring the RAG remains effective and efficient in real-time applications. Let's delve into the core auto evaluation metrics used in RAG pipelines, spanning both the retrieval and generation phases.
RAG Pipeline Metrics
Retrieval Metrics
- Context Recall: This metric measures the percentage of relevant chunks successfully returned by the retrieval component.
- Context Precision: Context precision assesses the accuracy with which the retrieved chunks are classified as relevant.
Generation Metrics
Generation phase metrics focus on the output's faithfulness and relevance to the prompt, ensuring that the generated text adheres to factual correctness and pertinence.
- Faithfulness: Measures the count of sentences/phrases generated that depart from the factual correctness of the relevant chunks retrieved.
- Relevance: This metric evaluates the number of sentences/phrases generated that are not pertinent to the user's query, ensuring that the system's responses remain focused and on-topic.
Human Ingenuity: The Undeniable Asset
These automatic evaluation metrics are essential tools in the AI development toolkit, offering a quantitative measure of a RAG system's performance. However, they function best when complemented by nuanced human evaluation, which can capture the subtleties of language and context that automated systems might miss. The human element is critical throughout a RAG architecture for:
- Data Annotation and Chunking: Ensuring chunks are contextually intact and annotations are precise. Appen's data annotation services (Step B and C in the diagram) excel in this area.
- Model Training and Tuning: Refining models based on nuanced understanding and feedback. Appen's expertise in model training and tuning ensures optimal performance and monitoring for model drift.
- Quality Control: Overseeing the model's outputs for accuracy, helpfulness, and safety. Appen's quality assurance processes (Prompt/Response QA in the diagram – Steps 1 & 5) maintain the highest standards.
- Ensuring Contextual Integrity: Interpreting nuances and contexts that are currently beyond the grasp of AI. Appen's human-in-the-loop approach (Steps, 1, 3, and 5 in the Prompt/Response diagram) ensures contextual integrity.
- Safeguarding Against Errors: Continuous human oversight helps identify and correct errors or inaccuracies in real-time.
By integrating both auto evaluation metrics and human judgment, RAG systems can achieve a high degree of accuracy, relevance, and reliability, vital for real-world applications.
Partner with Appen for Unmatched RAG Expertise
Leveraging Appen's vast experience in data annotation, model training, and quality assurance, organizations can unlock the full potential of RAG architecture. Appen's tailored support encompasses every step of the RAG journey, from data preparation and chunk improvement to optimizing model responses. Partner with Appen to ensure your AI initiatives are not just innovative but are built on the solid foundation of accuracy, relevance, and human insight.
Conclusion
Effective AI systems require human-in-the-loop interactions across the entire AI lifecycle. One effective way to deploy AI models is through a RAG architecture. A RAG system allows AI teams to augment the language power of a foundation model with deeper domain expertise. Documents and data prepared for the RAG help a generalized foundation model understand more about domains on which it was never trained. The improvements and efficiency that RAG brings to an AI system rely on their own augmentation with humans to be honest, helpful, and harmless. Appen is here to help in all the ways described above, providing crucial human expertise and expert oversight at every stage of the RAG process, from data preparation to model evaluation and refinement.